node基础概念
1.跨域产生的原因以及解决方案
- 什么是
跨域?- 广义:指一个域下的文档或脚本试图去请求另一个域下的资源
- 狭义:浏览器不能执行其他网站的脚本,是由浏览器的同源策略限制的一类请求场景,从一个域名的网页去请求另一个域名的资源时,域名,端口,协议任一不同,都是跨域。
- 为什么会产生跨域?
跨域是因为浏览器的同源策略的限制,是浏览器的一种安全机制,服务端之间是不存在跨域的。所谓的同源指的是两个页面具有相同放入协议,主机和端口,三者任一不相同就会产生跨域。
跨域举例: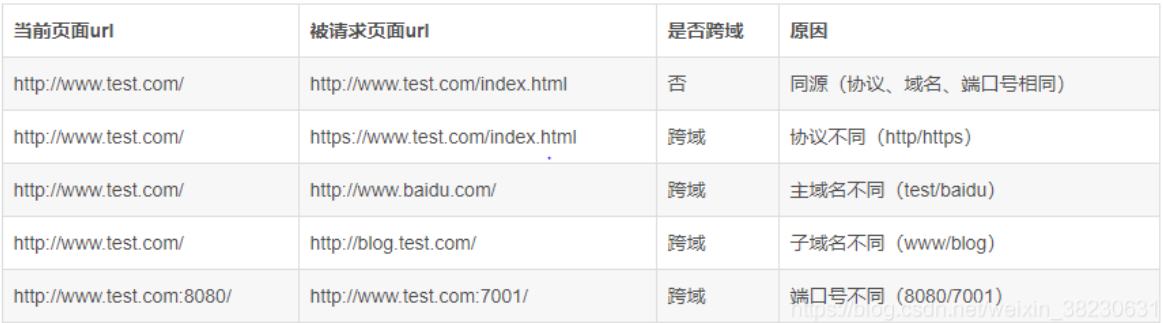
3. 跨域的解决方案
1. jsonp跨域
jsonp(JSON with Padding),是json的一种“使用模式”,可以让页面跨域读取数据,其本质是利用script标签的开放策略,浏览器传递callback参数到后端,后端返回数据时会将callback参数作为函数名来包裹数据,从而浏览器久可以跨域请求数据并制定函数来自动处理返回数据。
2. 跨域资源共享(cors)
跨域资源共享是一个W3C标准,允许浏览器向跨域服务器发送请求,从而客服ajax只能同源使用的限制。CORS需要浏览器和服务器同时支持。目前,所有主流浏览器是同XMLHttpRequest对象都可支持该功能,IE8和IE8需要使用XDomainRequest对象进行兼容。
CORS整个通信过程都是浏览器自动完成,浏览器一旦发现ajax请求跨源,就会自动在头信息中增加Origin字段,用来说明本次请求来自哪个源(协议+域名+端口)。因此,实现CORS通信的关键是服务器,需要服务器配置Access-Control-Allow-Origin头信息。当CORS请求需要携带cookie时,需要服务端配置Access-Control-Allow-Credentials头信息,前端也需要设置withCredentials。
3. 服务器代理
服务器代理,顾名思义即在发送跨域请求时,后端进行代理中转请求至服务器端,然后将获取的数据返回给前端。
一般适用于以下场景:
- 针对IE7及以下浏览器摒弃Flash插件的情况,配置代理接口与前端页面同源,并中转目标服务器接口,则ajax请求不存在跨域问题。
- 外网前端页面无法访问内网接口,配置代理接口允许前端页面访问,并中转内网接口,则外网前端页面可以跨域访问内网接口。
2.body-parser这个中间件是做什么用的?
body-parser是一个Node.js中间件,用于解析HTTP请求中的请求体(RequestBody),并将其转化为JSON格式或其它格式的数据对象。它可以帮助开发者方便的从POST,PUT,DELETE等请求中获取请求体数据,并进行相应的处理。具体来说,body-parser支持以下几种请求体数据格式:
1. JSON格式:通过json()方式解析JSON格式的请求体数据,并将其转换为JS对象
2. URL编码格式:通过urlencoded()方法解析URL编码格式的请求体数据,并将其转换为JS对象
3. 多部分数据格式:通过multipart()方法解析多部份数据格式的请求体数据,并将其转换为JS对象。
例子:简单实用body-parser解析请求体数据的示例代码:
1 | const express = require('express'); |
上面使用body-parser中间件分别解析了URL编码格式和JSON格式的请求体数据,并通过req.body获取请求体数据对象。在POST请求处理的函数中,打印了用户输入的用户名和密码,并返回了一个登录成功对的响应消息。
在使用body-parser中间件时需要根据实际情况选择合适的解析方法,并注意配置参数,以防止出现安全漏洞和错误数据。同时,在处理HTTP请求时,需要对请求体数据进行有效性验证和安全性检查,以保证数据的可靠性和完整性。
3.什么是Koa?
nodejs中除了express框架,另一个非常流行的Node Web服务器框架就是Koa。
Koa是一个精简的node框架,最大的特点是独特的中间件流程控制,典型的洋葱模型。
4.对Koa洋葱模型的理解
Koa框架是一个Node.js的Web应用程序框架,它通过中间件机制实现了业务逻辑的分层和复用。Koa中使用的中间件机制被称为洋葱模型,其核心思想是将HTTP请求和响应对象一次传递给各个中间件函数,形成一条类似于洋葱的管道,最终返回响应结果。
具体来说,Koa 洋葱模型的处理流程可以大致分为四个阶段:
请求阶段:从外到内依次执行请求相关的中间件,例如解析请求体、设置响应头等操作。业务阶段:执行业务逻辑相关的中间件,例如处理授权、验证身份、路由分发等操作。响应阶段:从内到外依次执行响应相关的中间件,例如格式化响应数据、设置响应头等操作。错误处理阶段:如果在前面的中间件过程中出现了错误,则会跳过后续中间件并交给错误处理中间件来处理异常情况。
在这个过程中,每个中间件都可以根据需要对请求和响应对象进行修改、扩展、封装等操作,并将控制权传递给下一个中间件,形成了一条流水线式的处理模式。这种设计可以大大提高代码的复用和可读性,同时也方便了对程序行为进行监控、调试和优化。
总之,Koa 洋葱模型是一种基于中间件机制的 Web 应用程序开发方法,它通过将请求和响应对象依次传递给各个中间件函数,实现了业务逻辑的分层和复用,并且具有灵活、可扩展和高效的特点。



